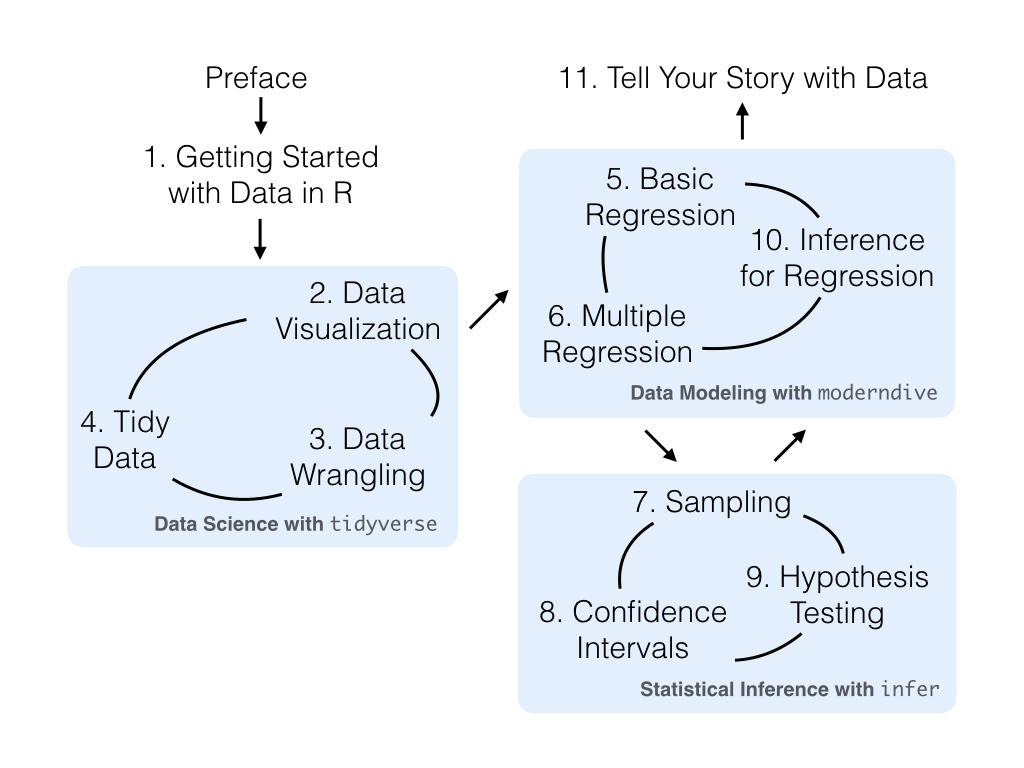
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| flights %>%
filter(dest=='PDX') %>%
dim()
## [1] 1354 19
weather %>%
summarise(mu = mean(wind_speed, na.rm=TRUE))
## # A tibble: 1 x 1
## mu
## <dbl>
## 1 10.5
weather %>%
group_by(month) %>%
summarise(mu = mean(wind_speed, na.rm=TRUE))
## # A tibble: 12 x 2
## month mu
## * <int> <dbl>
## 1 1 11.2
## 2 2 12.7
## 3 3 12.9
## 4 4 11.1
## 5 5 9.52
## 6 6 10.3
## 7 7 9.58
## 8 8 8.61
## 9 9 8.91
## 10 10 9.70
## 11 11 11.8
## 12 12 10.1
weather %>%
mutate(ws2 = wind_speed - mean(wind_speed)) %>%
head(1)
## # A tibble: 1 x 16
## origin year month day hour temp dewp humid wind_dir wind_speed wind_gust
## <chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 10.4 NA
## # ... with 5 more variables: precip <dbl>, pressure <dbl>, visib <dbl>,
## # time_hour <dttm>, ws2 <dbl>
flights %>%
group_by(dest) %>%
summarise(num_flights = n()) %>%
arrange(desc(num_flights)) %>%
head(1)
## # A tibble: 1 x 2
## dest num_flights
## <chr> <int>
## 1 ORD 17283
flights %>%
inner_join(airlines, by ='carrier') %>%
head(2)
## # A tibble: 2 x 20
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 533 529 4 850 830
## # ... with 12 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
## # hour <dbl>, minute <dbl>, time_hour <dttm>, name <chr>
flights %>%
select(year, everything()) %>%
head(1)
## # A tibble: 1 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## # ... with 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
## # hour <dbl>, minute <dbl>, time_hour <dttm>
flights %>%
top_n(n =10, arr_time) %>%
head(2)
## # A tibble: 2 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 2209 2155 14 2400 2337
## 2 2013 1 5 2116 2130 -14 2400 18
## # ... with 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
## # hour <dbl>, minute <dbl>, time_hour <dttm>
|