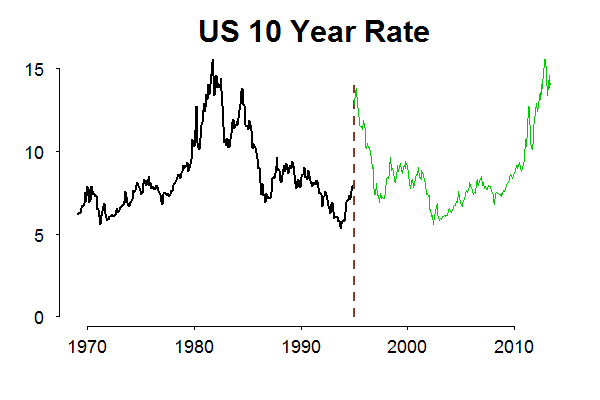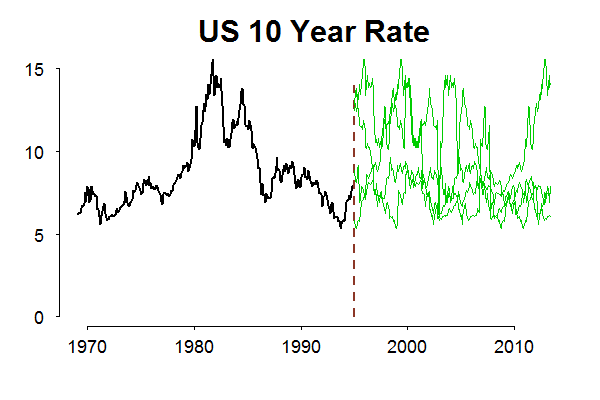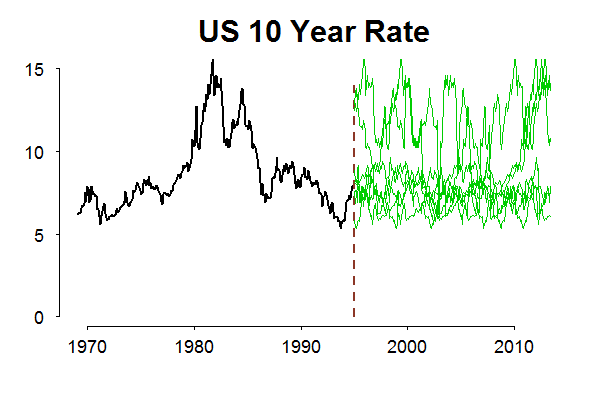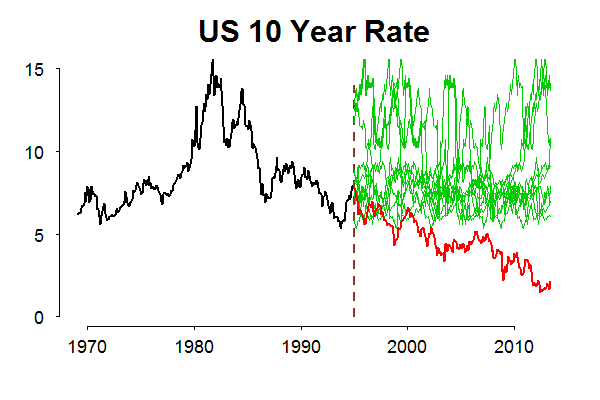
A Simple Long Memory Model of Realized Volatility
The paper titled, “A Simple Long Memory Model of Realized Volatility ”, is one of the most cited papers in the area of long memory volatility models.
One typically assumes that log prices follow an arithmetic random walk. In this kind of set up, it has been shown in the previous research that integrated volatility of Brownian motion can be approximated to any arbitrary precision using the sum of intraday squared returns. In fact this statement is applicable at a more general class of stochastic processes – finite mean semi martingales (includes Ito processes, pure jump processes, jump diffusion processes). Sum of intraday squared returns, ``Realized volatility, is a nonparametric measure that asymptotically converges to the integrated volatility as the sampling frequency increases. The flip side to this utopian scenario is the microstructure noise that one needs to contend with as the time scales become finer. Noise introduces a significant bias in the RV estimate. Hence one has to make a tradeoff between measurement noise and unbiasedness. In many papers, researchers have used anywhere between 15 min to 30 min intervals, as they might have observed that as the shortest return interval at which the resulting volatility is still not biased. Another approach that can be adopted to deal with the microstructure noise is to filter away the noise using the autocovariance structure of k tick aggregated returns. Well one might have to search a grid to get an optimal k to begin with. In an earlier paper by Corsi , one such filtering method is described.



 Takeaway:
Takeaway:






 Takeaway :
Takeaway :