Data Dredging
Stumbled on to an interesting comment on crossvalidated which I think is a nice way to warn against using techniques such as best subset regression, forward step regression, backward step regression etc.
Wanting to know the best model given some information about a large number of variables is quite understandable. Moreover, it is a situation in which people seem to find themselves regularly. In addition, many textbooks (and courses) on regression cover stepwise selection methods, which implies that they must be legitimate. Unfortunately however, they are not, and the pairing of this situation and goal are quite difficult to successfully navigate. The following is a list of problems with automated stepwise model selection procedures (attributed to Frank Harrell, and copied from here ):
It yields R-squared values that are badly biased to be high.
The F and chi-squared tests quoted next to each variable on the printout do not have the claimed distribution.
The method yields confidence intervals for effects and predicted values that are falsely narrow; see Altman and Andersen (1989).
It yields p-values that do not have the proper meaning, and the proper correction for them is a difficult problem.
It gives biased regression coefficients that need shrinkage (the coefficients for remaining variables are too large; see Tibshirani [1996]).
It has severe problems in the presence of collinearity.
It is based on methods (e.g., F tests for nested models) that were intended to be used to test prespecified hypotheses.
Increasing the sample size does not help very much; see Derksen and Keselman (1992).
It allows us to not think about the problem.
It uses a lot of paper.
The question is, what’s so bad about these procedures / why do these problems occur? Most people who have taken a basic regression course are familiar with the concept of regression to the mean , so this is what I use to explain these issues. (Although this may seem off-topic at first, bear with me, I promise it’s relevant.)
Imagine a high school track coach on the first day of tryouts. Thirty kids show up. These kids have some underlying level of intrinsic ability to which neither the coach, nor anyone else, has direct access. As a result, the coach does the only thing he can do, which is have them all run a 100m dash. The times are presumably a measure of their intrinsic ability and are taken as such. However, they are probabilistic; some proportion of how well someone does is based on their actual ability and some proportion is random. Imagine that the true situation is the following:
1 2 3set.seed(59) intrinsic_ability = runif(30, min=9, max=10) time = 31 - 2*intrinsic_ability + rnorm(30, mean=0, sd=.5)The results of the first race are displayed in the following figure along with the coach’s comments to the kids.
Note that partitioning the kids by their race times leaves overlaps on their intrinsic ability–this fact is crucial. After praising some, and yelling at some others (as coaches tend to do), he has them run again. Here are the results of the second race with the coach’s reactions (simulated from the same model above):
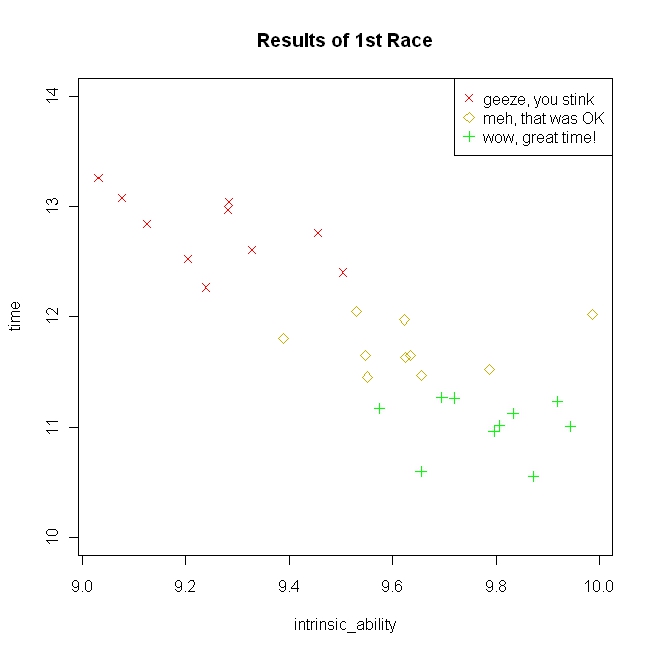
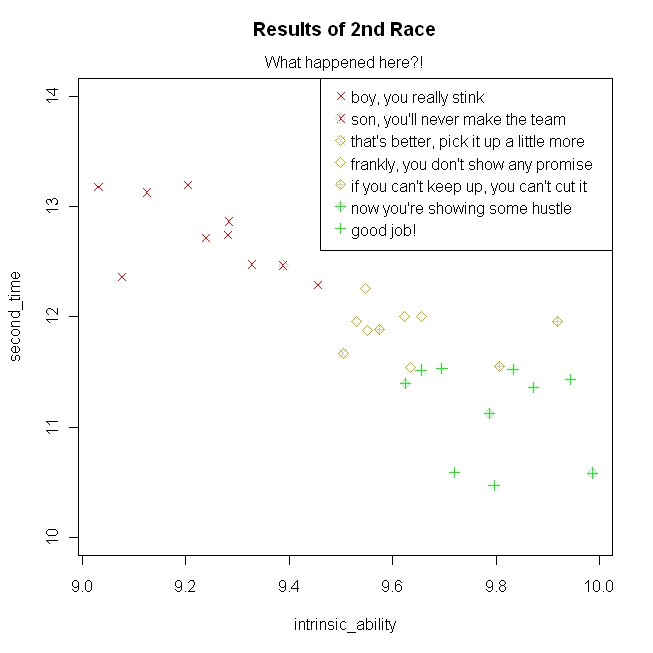
Notice that their intrinsic ability is identical, but the times bounced around relative to the first race. From the coach’s point of view, those he yelled at tended to improve, and those he praised tended to do worse (I adapted this concrete example from the Kahneman quote listed on the wiki page), although actually regression to the mean is a simple mathematical consequence of the fact that the coach is selecting athletes for the team based on a measurement that is partly random.
Now, what does this have to do with automated (e.g., stepwise) model selection techniques? Developing and confirming a model based on the same dataset is sometimes called data dredging. Although there is some underlying relationship amongst the variables, and stronger relationships are expected to yield stronger scores (e.g., higher t-statistics), these are random variables and the realized values contain error. Thus, when you select variables based on having higher (or lower) realized values, they may be such because of their underlying true value, error, or both. If you proceed in this manner, you will be as surprised as the coach was after the second race. This is true whether you select variables based on having high t-statistics, or low intercorrelations. True, using the AIC is better than using p-values, because it penalizes the model for complexity, but the AIC is itself a random variable (if you run a study several times and fit the same model, the AIC will bounce around just like everything else). Unfortunately, this is just a problem intrinsic to the epistemic nature of reality itself.