Quick Start Guide to Large Language Models - Book Review
Contents
This blog post summarizes the book titled “Quick Start Guide to Large Language Models”, by Sinan Ozdemir

Context
LLMs have become quite a rage in the last few years, thanks to the release of ChatGPT that has captured the imagination of one and all. Every financial services company worth its salt is exploring ways to explore this technology to deliver something new to its customers. Needless to say, financial data providers have also joined the race and are developing LLMs. In that context, this book is timely and serves as a good resource for quickly getting up to speed. In this blogpost, I will try to summarize some of the main points from each of the chapters in the book
Overview of Large Language Models
The following are some of the main points mentioned in this chapter
- In 2017, a team at Google Brain introduced deep learning model called Transformer. Since then the Transformer has become the standard for tackling various NLP tasks in academia and industry
- LLMs are AI models that are usually derived from the Transformer architecture and are designed to understand and generate human language, code and much more.
- Brief history of modern NLP
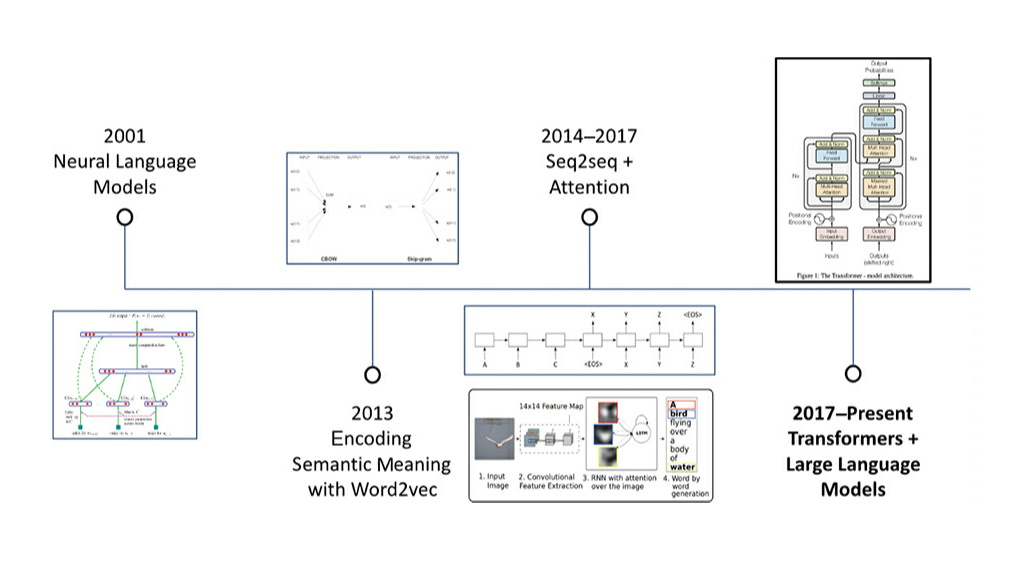
- Transformer architecture is quite impressive as it can be highly parallelized and scaled in ways that previous state-of-the-art NLP models could not be
- Language modeling is a subfield of NLP that involves the creation of statistical/deep learning models for predicting the likelihood of a sequence of tokens in a specified vocabulary
- There are generally two kinds of language modeling tasks
- Auto encoding tasks
- Autoregressive tasks
- Autoregressive language models are trained to predict the next token in a sentence, based on only the previous tokens in the phrase. These models correspond to the decoder part of the Transformer model, with a mask being applied to the full sentence so that the attention heads can see only the tokens that came before
- Autoencoding language models are trained to reconstruct the original sentence from a corrupted version of the input. These models correspond to the encoder part of the transformer model and have access to the full input without any mask
- LLMs are language models may be either autoregressive, autoencoding, or a combination of the two. Modern LLMs are usually based on the transformer architecture but can also be based on another architecture
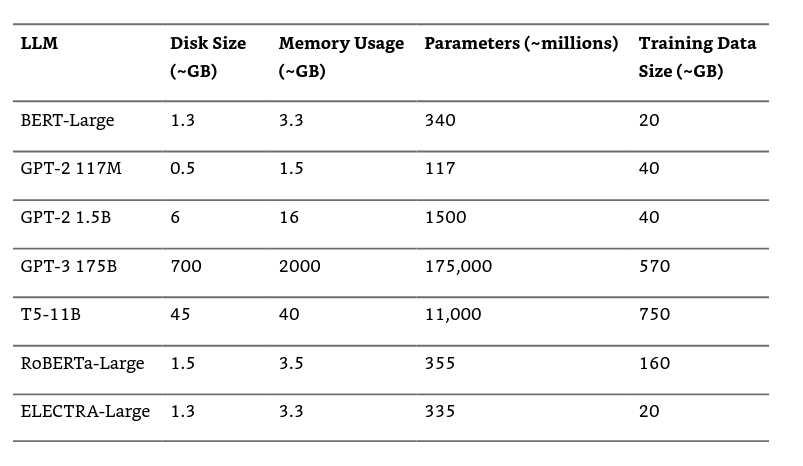
- Comparison of LLM model parameters
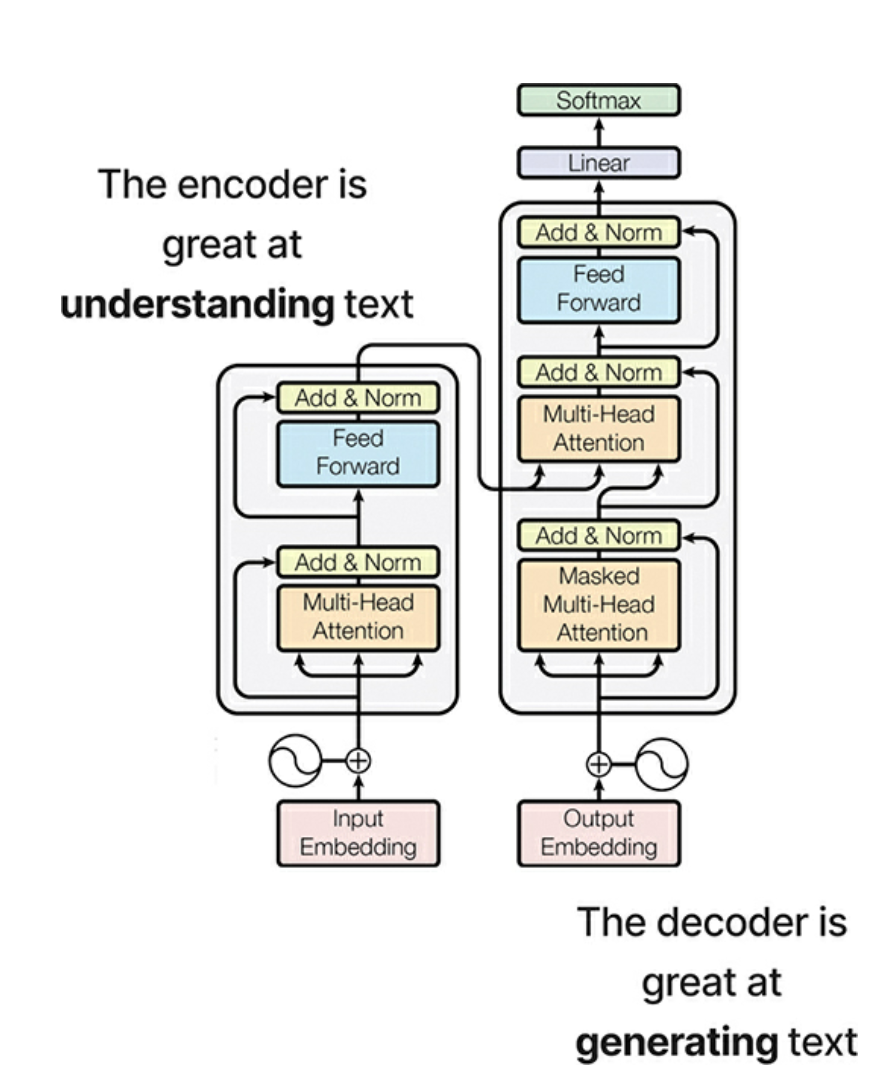
- The original Transformer architecture, as devised in 2017, was a
sequence-to-sequence model, with two components
- An encoder, which is tasked with taking in raw text, splitting it up into its core components, converting those components into vectors and using attention to understand the context of the text
- A decoder, which excels at generating text by using a modified type of attention to predict the next best token
- The encoder is great at understanding text and decoder is great at generating text
- Models like BERT and GPT dissect the transformer into only an encoder and a decoder so as to build models that excel in understanding and generating
- LLMs can be categorized into three main buckets
- Autoregressive models, such as GPT, which predict the next token in the sentence based on the previous tokens. These LLMs are effective at generating coherent free-text following a given context
- Autoencoding models, such as BERT, which build a bidirectional representation of a sentence by masking some of the input tokens and trying to predict them from the remaining ones. These LLMs are adept at capturing contextual relationships between tokens quickly at scale, which makes them great candidates for text classification tasks
- Combination of autoregressive and autoencoding, such as T5, which can use the encoder and decoder to be more versatile and flexible in generating text. Such combination models can generate more diverse and creative text in different contexts
- Every LLM on the market has been pretrained on a large corpus of text data and on specific language modeling-related tasks. During the pre-training, the LLM tries to learn and understand general language and relationships between words.
- BERT was also pre-trained on two specific language modeling tasks
- Masked Language Modeling: This task helps BERT recognize token interactions within a single sentence
- Next Sentence prediction: This task helps BERT understand how tokens interact with each other between sentences
- Pre-training on these corpora allowed BERT to learn a rich set of language features and contextual relationships.
- Transfer learning allows LLMs to be fine-tuned for specific tasks with much smaller amounts of task-specific data than would be required if the model were trained from scratch
- The general transfer learning loop involves pre-training a model on a generic dataset on some generic self-supervised task and then fine-tuning the model on a task-specific dataset
- Before popularization of attention, most neural networks processed all inputs equally and the models relied on a fixed representation of the input to make predictions. Modern LLMs that rely on attention can dynamically focus on different part of the sequences, allowing them to weigh the importance of each part in making predictions
- Tokenization involves breaking text down into the smallest unit of understanding-tokens. These tokens are the pieces of information that are embedded into semantic meaning and act as inputs to the attention calculations
- Usual NLP techniques such as stop-words removal, stemming and truncation are not used while feeding input to LLMs
- Every LLM has to deal with words it has never seen before. How an LLM tokenizes text can matter if we care about the token limit on an LLM. In the case of BERT, sub-words are denoted with a preceding ‘##’, indicating they are part of a single word and not the beginning of a new word
- Alignment in language models refers to how well the model can respond to input prompts that match the user’s expectations. Standard language models predict the next word based on the preceding context, but this can limit their usefulness for specific instructions or prompts
- RL from human feedback is a popular method of aligning pre-trained LLMs that uses human feedback to enhance their performance. It allows the LLM to learn from a relatively small, high-quality batch of human feedback on its own outputs, thereby overcoming some of the limitations of traditional supervised learning.
- Popular LLMs
- BERT uses the encoder of the transformer and ignores the decoder to become exceedingly good at processing or understanding massive amounts of text very quickly relative to others, slower LLMs that focus on generating text one token at a time. BERT-derived architectures, therefore, are best for working with and analyzing large corpora quickly when we don’t need to write free-text. It doesn’t classify text or summarize documents, but it is often used as a pre-trained model for downstream NLP tasks
- GPT is an autoregressive model that uses attention to predict the next token in a sequence based on the previous tokens. It relies on the decoder portion of the transformer and ignores the encoder, so it is exceptionally good at generating text one token at a time
- T5 is a pure encoder/decoder transformer model that was designed to perform several NLP tasks, from text classification to text summarization and generation, right off the shelf. T5 is both the encoder and the decoder of the transformer, so it is highly versatile in both processing and generating text.
- BioGPT - Domain Specific LLMs
- this model was trained on a dataset of more than 2 million biomedical research articles, making it highly effective for a wide range of biomedical NLP tasks. BioGPT whose pre-training encoded biomedical knowledge and domain specific jargon in to the LLM, can be finetuned on smaller datasets, making it adaptable for specific biomedical tasks and reducing the need for large amounts of labeled data
- Three ways LLMs can be used
- Using a pre-trained LLMs underlying ability to process and generate text with no further fine-tuning as part of larger architecture
- Fine-tuning a pre-trained LLM to perform a very specific task using transfer learning
- Asking a pre-trained LLM to solve a task it was pre-trained to solve or could reasonably intuit
Semantic Search with LLMs
- AI companies across the world can offer text embeddings based on LLMs
- In the traditional world of search engines, a query by the user can contain generic terms and hence the results could vary across domains. Depending on how the search engine is built, you can have hits that are completely different from one engine to another
- Semantic search is different in the sense that it takes a bunch of words and understands the meaning and context of your query and matches against the meaning and context of the documents that are available to retrieve.
- Asymmetric search is a term that denotes the difference in the user query and the relevant documents that need to be searched. The query is usually smaller in size as compared to the relevant size of the documents that need to be searched for
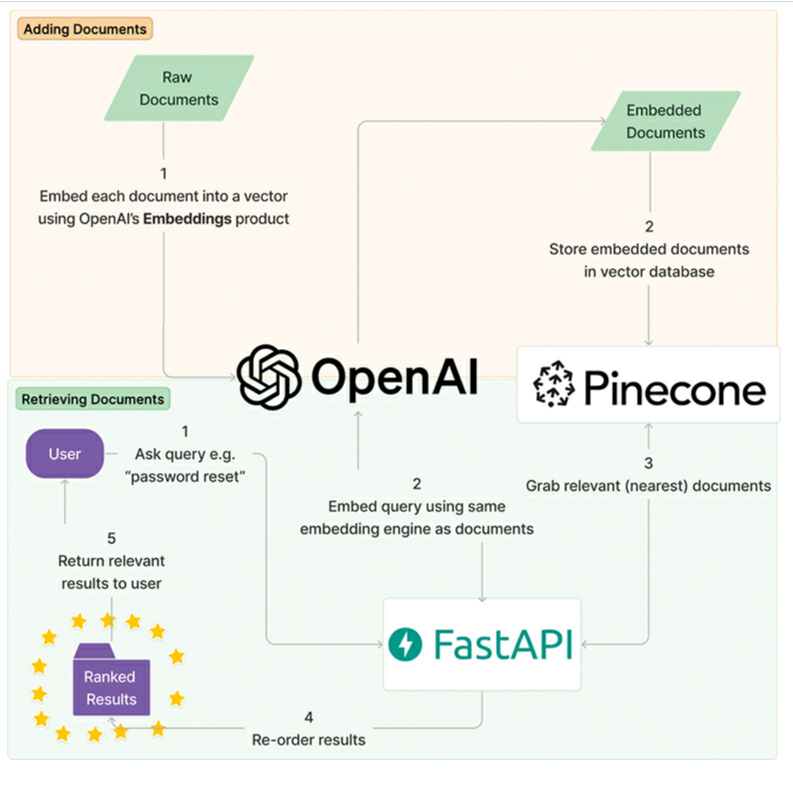
- Overview of an asymmetric semantic search system
- Collect documents for embeddings
- Create text embeddings
- Store embeddings in a database
- Take the user query, cleanse it up
- Retrieve the relevant documents via embedding similarity
- Re-rank the candidate documents if necessary
- Return the final results
- There are many embedding products available in the market
- Building a embeddings database means to look at a knowledge base and create embeddings for the content so that similar content lies closer in the embedding space
- Embedding longer texts such as documents is also possible and here are a few
ways to get it done
- Max Token window chunking with no overlap
- Max token widow chunking with overlap
- Chunking on natural delimiters
- Clustering to create semantic documents
- Use entire documents without chunking
- Vector database is a database storage system that is specifically designed to both store and retrieve vectors quickly. This type of database is useful for storing the embeddings generated by an LLM that encode and store the semantic meaning of our documents or chunks or documents. By storing embeddings in a vector database, we can efficiently perform nearest-neighbor searches to retrieve similar pieces of text based on their semantic meaning
- Pinecone is a vector database that is designed for small to medium-sized datasets.
- There are open-source alternatives to Pinecone can be used to build a vector
database for LLM embeddings. Pgvector is a PostgreSQL extension that adds
support for vector datatypes and provides fast vector operations. Another
option is
Weaviate, a cloud-native, open source vector database that is designed for machine learning applications - After retrieving the relevant results, it makes sense to rerank them to ensure that the most relevant results are shown to the user. One way to re-rank results is by using a cross-encoder, a type of transformer model that takes pairs of input sequences and predicts a score indicating how relevant the second sequence is to the first
- In a task such as question answering, the decision criteria could be
- What embedding engine should be used ?
- Should one use a model for re-ranking method ?
- Should the model for re-ranking be finetuned for specific datasets ?
First Steps with Prompt Engineering
- Prompt engineering involves crafting inputs to LLMs that effectively communicate the task at hand to the LLM, leading it to return accurate and useful outputs. Prompt engineering is a skill that requires an understanding of the language, the specific domain being worked on, and the capabilities and limitations of the LLM being used
- The key thing to understand about LLM training is “Alignment”. It is important to have RLAIF(Reinforcement learning from AI Feedback) or RLHF(Reinforcement learning from Human Feedback) in the model training process. These alignment techniques help in model’s ability to understand and respond to specific prompts effectively.
- The first and foremost important rule for prompt engineering for instruction-aligned language models is to be clear and direct about what you are asking
- Few-shot learning is a powerful technique that involves providing an LLM with a few examples of a task to help it understand the context and nuances of the problem
- Output structuring is a way to instruct LLMs to produce the output in a specific way to make it easier to work and integrate into other systems
- Prompting Personas is another way to take advantage of LLMs. Developers can better control the output of the model if the prompts mention about the persona of the end user
- Why do we need prompt engineering ? Prompts are highly dependent on the architecture and training of the language model, meaning that what works for one model may not work for another.
- There are open-source models like GPT-J and FLAN-T5 that can be used to generate high-quality text output just like the closed source counterparts. Open source models offer greater flexibility and control over prompt engineering, enabling developers to customize prompts and tailor output to specific use cases during fine-tuning
- Here are a set of visuals explaining the way vector databases are using in the LLM workflow for an end user application
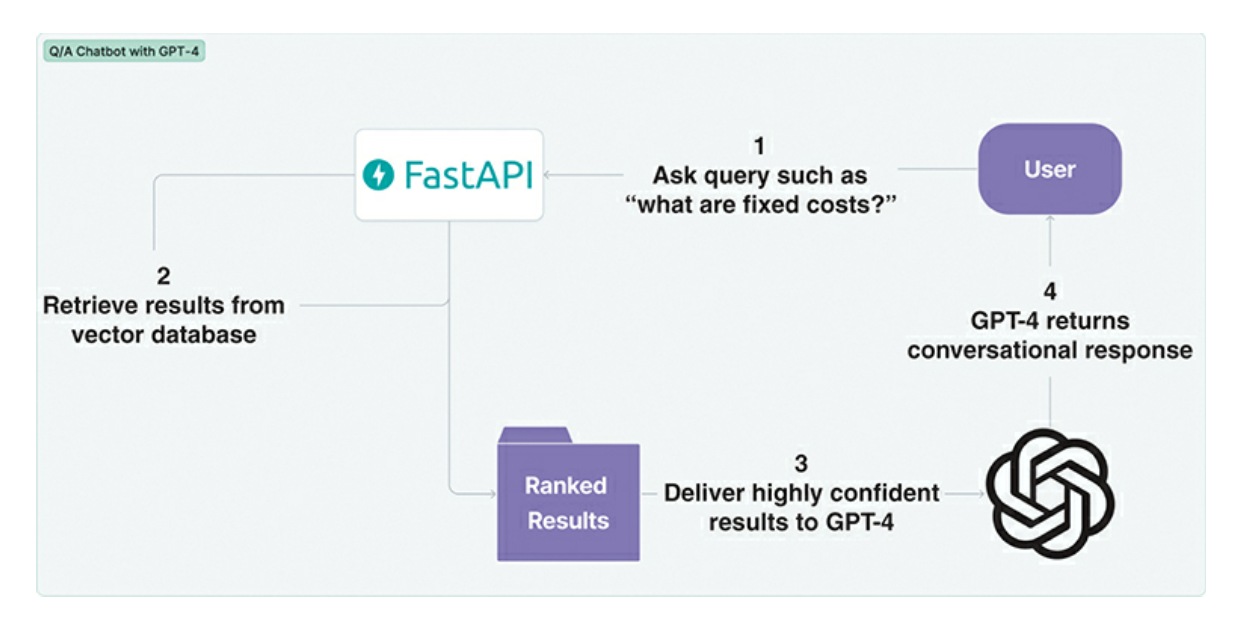
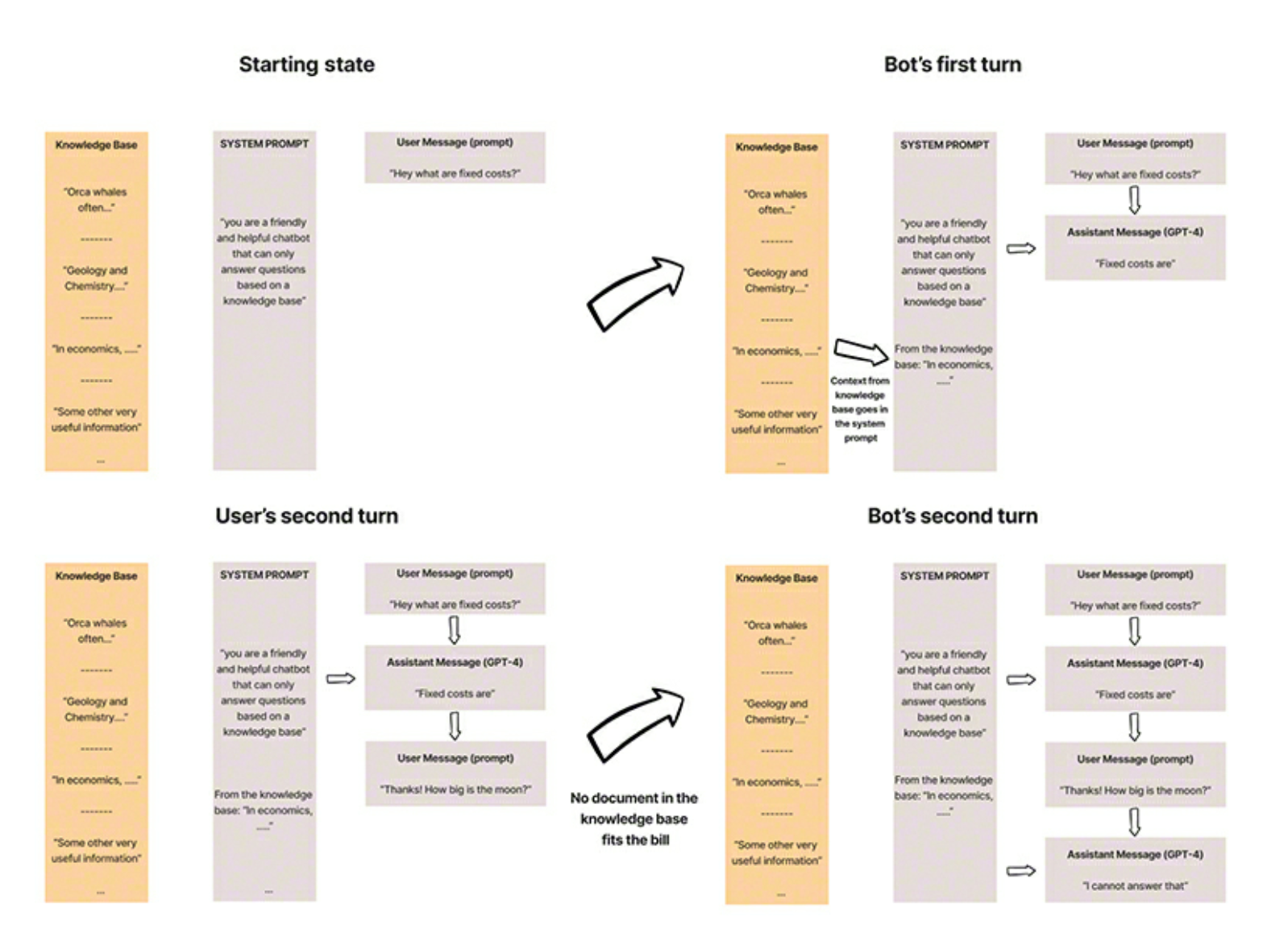
- The knowledge from a vector database are used to aid the System prompt. This system prompt along with the knowledge from the vector database are then used in the interactive session with the user
- There is a strong correlation between proficient prompt engineering and effective writing. It is very important process for improving the performance of a language models. By designing and optimizing prompts, you can ensure that your language models will better understand and respond to user inputs
Optimizing LLMs with Customized Fine-Tuning
The following are the main points mentioned in the chapter:
- Fine tuning updates off-the-shelf models and empowers them to achieve higher-quality results; it can lead to token savings and often lower latency requests
- Running inference with fine-tuned models can be extremely cost-effective in the long run, particularly when working with smaller models
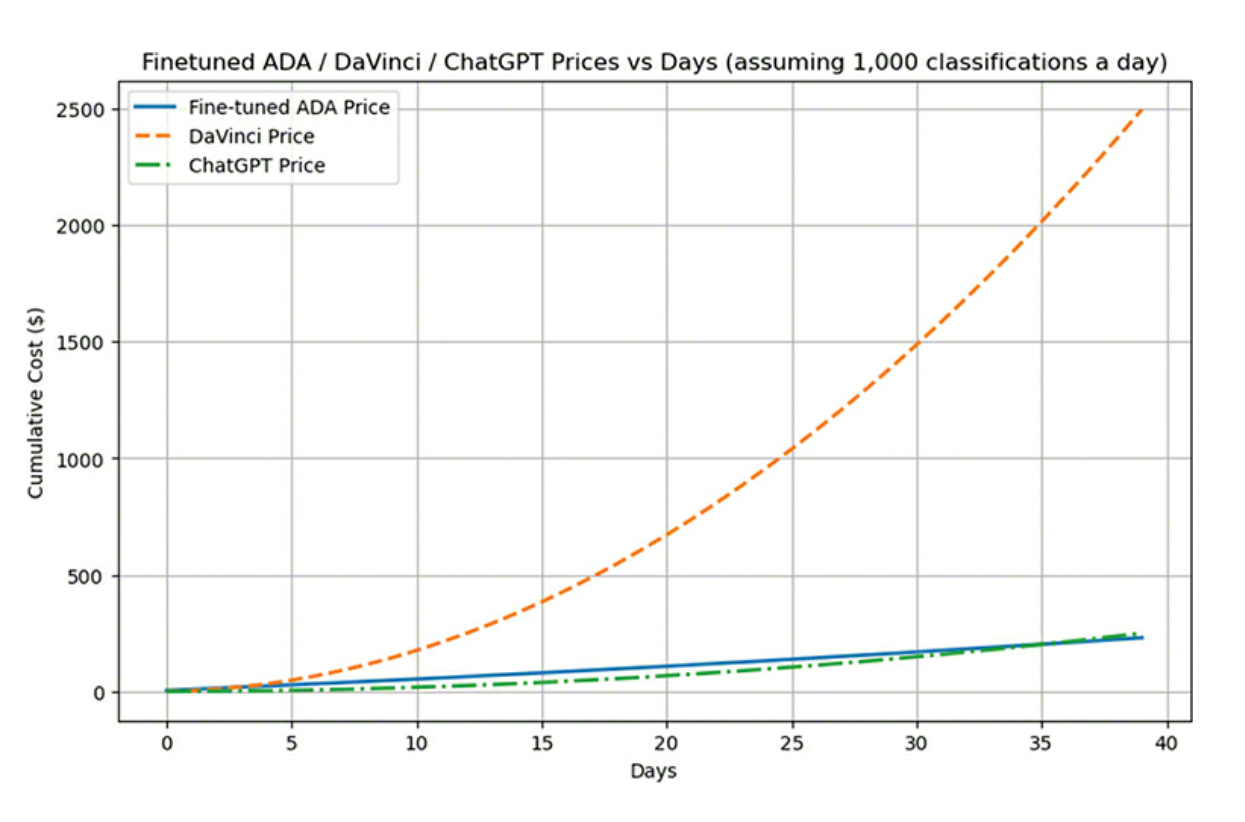
- The process of fine tuning can be broken down into a few steps
- Collecting labeled data
- Hyperparameter selection
- Model adaptation
- Evaluation and iteration
- Model implementation
- OpenAI’s infrastructure has been specifically designed to facilitate fine tuning process. OpenAI has developed tools and resources to make it easier for researchers and developers to fine-tune smaller models, such as Ada and Baggage
- GTP3-API offers developers access to one of the most advanced LLMs available. This API provides a range of fine-tuning capabilities, allowing users to adapt the model to specific tasks, languages and domains
- The training data for OpenAI is provided in the form of OpenAI JSONL format. The API expects the training data to be in JSONL format. For each example in the training and validation sets, create a JSON object with two fields - prompt and completion, the format is the input and latter is the target class.
- OpenAI CLI simplifies the process of fine-tuning and interacting with the API. The CLI allows you to submit fine-tuning requests, monitor training progress and manage your models
- One can use the OpenAI CLI to send custom data and finetune the model for a
specific task such as sentiment classification or categorization of text in to
set of classes. To do this, one will need
- Identify the fine tuned model
- Use the fine-tuned model in the OpenAPI CLI requests
- Adapt any specific application logic
The following captures the workflow:
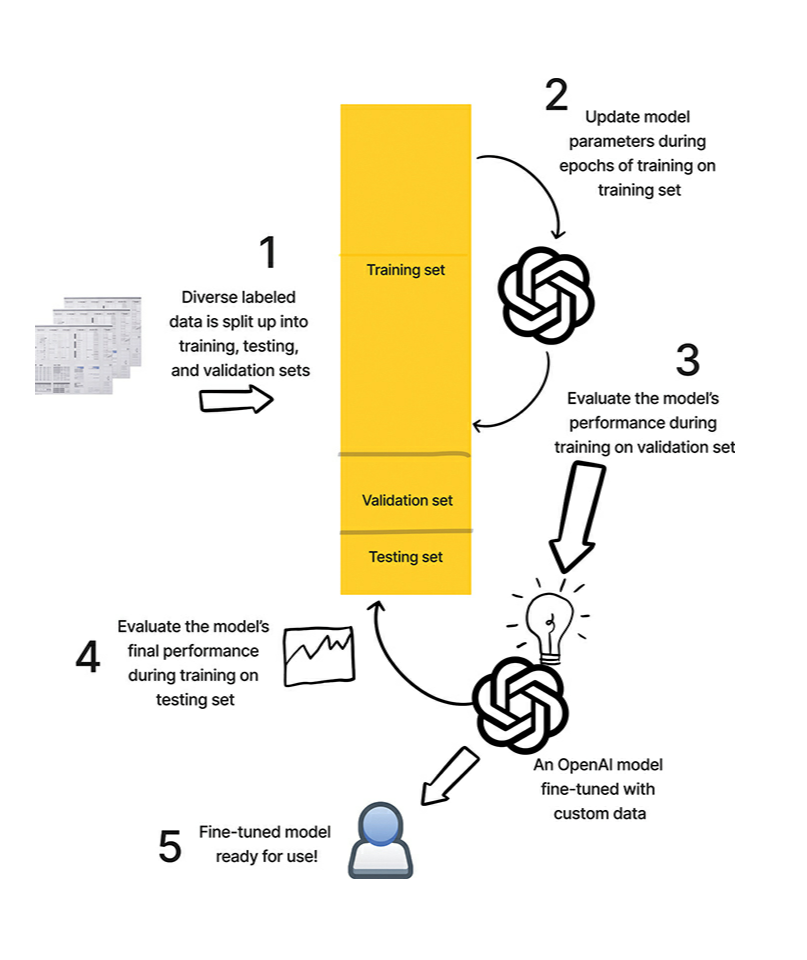
Advanced Prompt Engineering
- Prompt injection is a type of attack that occurs when an attacker manipulates the prompt given to an LLM in an effort to generate biased or malicious outputs
- Using prompt injection, some one could potentially steal the prompt of a popular application using a popular LLM and create a clone with a near-identical quality of responses
- Example of prompt injection

- Prompt engineering methods
- Input/Output validation
- Create validation pipeline that leverages yet another LLM to detect and filter out offensive behaviors
- Batch Prompting
- Prompt chaining
- prevent Prompt stuffing
- prevent Prompt injection
- Fantastic walk through of prompt engineering for effective inference of a
grade school math dataset comprising 8500 linguistically diverse math word
problems. There are several iterations that the author tries out
- Plain simple prompt of stating the question
- State the question and ask the LLM to reason it out
- State the question, ask the LLM to reason and provide a few-shot random examples
- State the question, ask the LLM to reason and provide a few-shot semantically similar examples
- Iterate on various number of few-shot examples to be provided
- Advanced prompting techniques can enhance the capabilities of LLMs they are both challenging and rewarding. Dynamic few-shot learning, chain-of-thought prompting, and multimodal LLMs can broaden the scope of tasks that can be tackled effectively. One can also implement security measures used other models as an output validator or using chaining to prevent injection attacks
Customizing Embedding and Model Architectures
The usecase mentioned in the chapter highlights all the previous concepts mentioned in the previous sections. The author tries to build a recommendation engine based on LLMs
- Recommendation engines can be broadly categorized in to two main approaches: content-based and collaborative filtering.
- Content based recommendation focus on the attributes of the items being recommended, utilizing item features to suggest similar content to users based on their past interaction
- Collaborative filtering capitalizes on the preferences of users, generating
recommendations by identifying patterns among users.
- system extracts relevant features from items, such as genre and builds a profile of the user. This profile helps the system understand the user’s preferences and suggest items with similar characteristics
- The key steps in modeling are
- construct text embedding models, either to use as-is or fine-tune them on user-preference data
- Define a hybrid approach to collaborative filtering and content filtering
- Fine tune the model based on a set of training set of user preference data
- Run the system on test data
- The chapter uses Sentence transformers library to fine tune open source embedders. It computes the Jaccard scores for any two pairs of anime IDs and then fine tunes a bi-encoder model. The goal is to create a recommendation system that can effectively identify similar anime titles based on the preference of promoters and not just because they are semantically similar. The embeddings will enable our model to take recommendations that are more likely to align with the tastes of the users who are enthusiastic about the content
- The key idea of this chapter is fine tuning embedder in a different way.
Usually in an embedder, two input animes are closer together if they are
semantically similar. However the chapter shows a way to create an embedder
that places pieces of embedded data near each other if they are similar in
terms of user preferences
- Use the content based aspects by using the features of anime as input
- Incorporate collaborative filtering by considering the jaccard score of promoters
Moving beyond Foundation Models
The chapter talks about one specific task, Visual question-answering and tries to illustrate concepts relating to combining various LLM models.
- VQA requires understanding and reasoning about both images and natural language. Given an image and a related question in NLP, the objective is to generate a textual response that answers the question correctly
- The chapter introduces three foundational models that will be used in constructing a multimodal system. The foundational models used are Vision Transformers, GPT-2 and DistilBERT
- The basic idea of the model is to pass the textual input through DistilBERT and the image through ViT, obtain the two embeddings and then use cross-attention.
- In the self-attention mechanisms used by transformers, the query, key and value components are crucial for determining the importance of each input token relative to others in the sequence. The query represents the token for which we want to compute attention weights, while the keys and values represent the other tokens in the sequence. The attention scores are computed by taking the dot product between the query and the keys, scaling it by a normalization factor, and then multiplying it by the values to create a weighted sum
- Every input token to a Transformer based LLM has an associated “query”, “key” and “value” representation. The scaled dot product attention calculation generates attention scores for each query token by taking the dot product with the key tokens; those scores are then used to contextualize the value tokens with proper weighting, yielding a final vector for each token in the input that is now aware of the other tokens in the input and how much it should be pay attention to them.
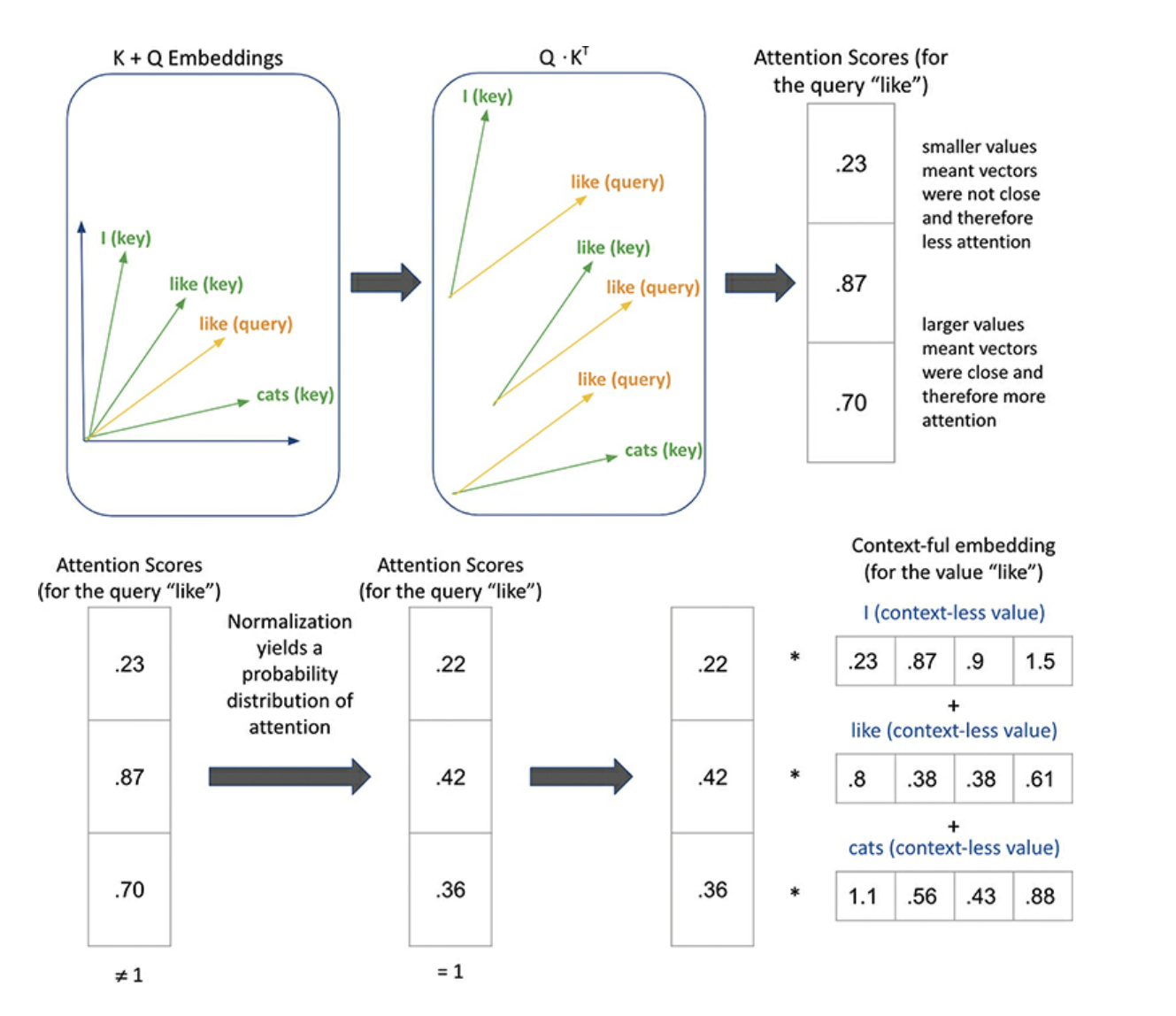
- In cross-attention, the Query, Key and Value matrices serve slightly different purposes. In this case, the query represents the output of one modality, while the keys and values represent the output of another modality. Cross-attention is used to calculate attention scores that determine the degree of importance given to the output of one modality when processing the other modality
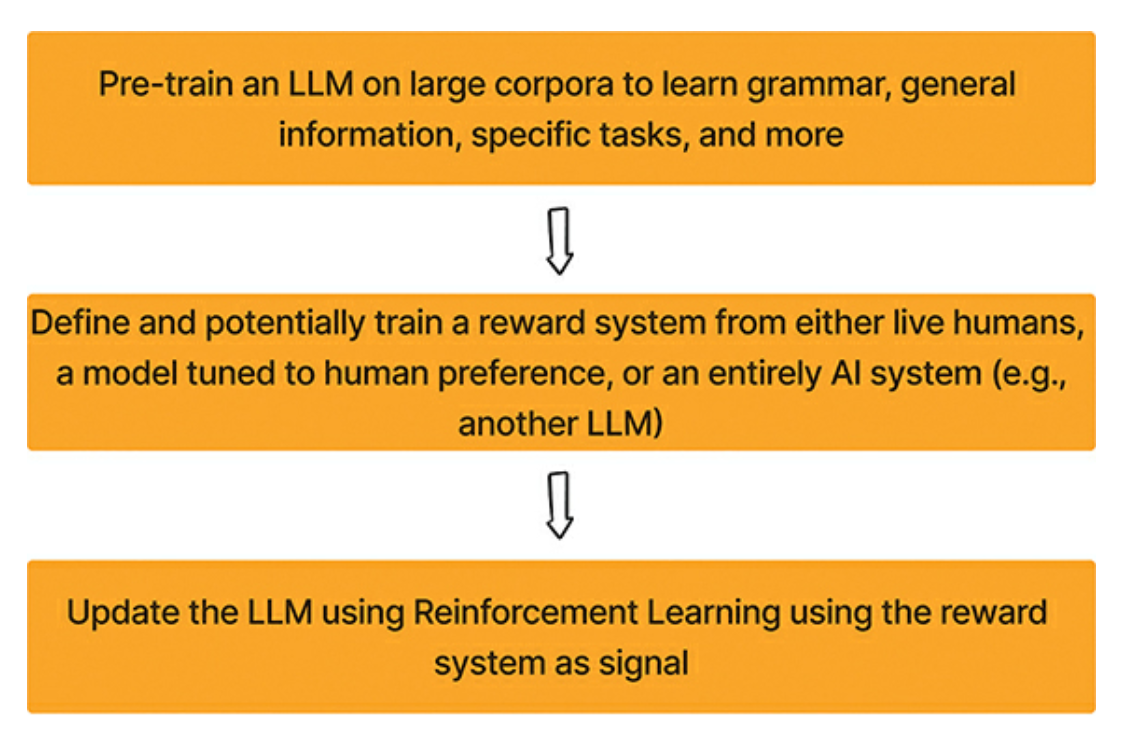
- By employing reinforcement learning methods, the author shows ways to fine tune the output of fine tuned model
- The core steps of RLHF are
- The author uses Transformer Reinforcement Library, an open source library that can be used to train transformer models with reinforcement learning
- The following visual captures all the steps explained in RHLF process:
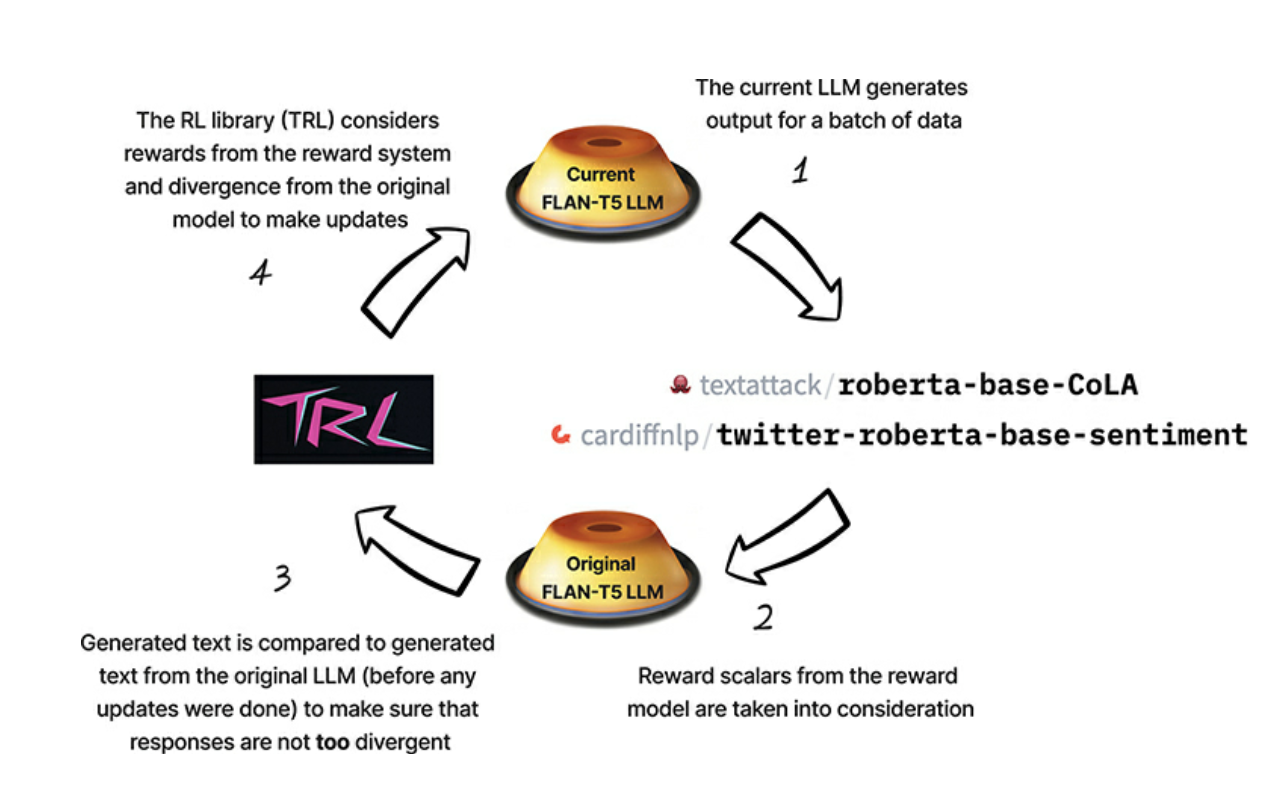
The chapter gives a wonderful overview of all the aspects of RHLF and gives acts as a nice primer to Alignment in the context of LLMs.
Advanced Open-Source LLM Fine-Tuning
This chapter highlights the importance of fine tuning an open source model as compared to using a closed source model. Here are some of the examples, the author uses to highlight various general techniques for finetuning.
Example - LaTeX generation with GPT2
- input data to fine tuning is 50 examples of English text to latex translation
- create relevant prompts using the above 50 examples
- use
AutoModelForCausalMLin thehuggingfacelibrary to tweak a GPT2 model - with 50 examples GPT2 was able to learn the translation quite quickly
SAWYER
- GPT2 model is open source with about 120 million parameters. Other versions of GPT such as GPT3 and GPT4 are not open source. GPT3 and GPT4 are closed source models and fine tuning them is very expensive
- This example involves fine-tuning GPT2 with a specific focus on instruction, defining a reward model to simulate human feedback and using that reward model to perform reinforcement learning to guide the model to improve over time, nudging it toward generating responses that are closer to what a human would prefer
- The following steps are done to accomplish the above task
- Take a pre-trained GPT-2 and make it understand the concept of answering a
question.
- Feed GPT-2 with a corpus of general single-shot question/answer examples from a subset of the Open Instruction Generalist dataset.
- OIG is a large open source instruction dataset that currently contains 43 million instructions
- A subset of 100,000 examples of instruction/response pairs are used
- Once the GPT-2 is clear about its task, we need to set up a system that can
assess its performance. This is where the reward model comes into play. It
is designed to rate responses that align with human preferences more favorably
- Utilize a new dataset of response comparisons, in which a single query has multiple responses attached to it, all given by various LLMs. Humans then grade each response from 1 to 10. With this human-labeled data, a reward model is specified.
- Create a custom loss function that captures the task objective
- Create a feedback mechanism that helps GPT-2 improve over time
- Take a pre-trained GPT-2 and make it understand the concept of answering a
question.
Takeaway
This chapter is superuseful to get a detailed idea of the ways in which one could take a pretrained GPT2 and finetune on custom datasets.
Moving LLMs into Production
- For closed-source LLMs, the deployment process typically involves interacting
with an API provided by the company that developed the model. This
model-as-a-service approach is convenient because the underlying hardware and
model management are abstracted away
- Cost projections will depend on API calls, model choice and model versions
- Deploying open-source LLMs is a different process, primarily because you have
more control over the model and its deployment. However this control also
comes with additional responsibilities related to preparing the model for
inference and ensuring it runs efficiently. Some of the aspects to be
considered are
- Preparing a model for inference
- Interoperability
- ONNX
- Quantization
- Pruning
- Knowledge Distillation
- Task specific versus task-agnostic distillation
- Temperature is a hyperparameter that is used to control the “softness” of
probability distribution
- Dividing the logits by the temperature before applying
softmaxis used to soften the probability distributions. When you divide the logits by the temperature before applyingsoftmax, this effectively “softens” the distribution. A higher temperature will make the distribution more uniform whereas a lower temperature will make it more peaked
- Dividing the logits by the temperature before applying
- In the case of open source models, cost projections involve considering both
the compute and storage resources
- compute costs
- storage costs
- scaling costs
- maintenance costs
Takeaway
I found this book very useful in giving a detailed overview of the LLM space. Agreed that this space is rapidly changing, the author gives several directions that a curious reader can further explore. The fact that there are code snippets that go with all the examples makes it far more interesting for a reader who wants to quickly put to use the knowledge gained for the book. There is so much of terminology that gets used around this space that it gets overwhelming. The author does a fantastic job of explaining the nuts and bolts without overwhelming the reader. Will definitely go over it again at some point in the future.